


NGram
문자열 중 지정된 길이의 문자들을 출력한다. 빠른 검색을 위해 사용될 용어들 (단어)들 미리 분리해서 역 인덱스에 저장한다.
공백을 사용하지 않는 언어들을 다룰 때 유용하다.
최소 값은 길이 1에서 최대 길이 2이다. (min_gram : 1, max_gram : 2)

"house" 를 2글자의 nGram으로 처리하면 "ho", "ou", "us", "se" 총 4개의 토큰이 추출된다. 이 4가지의 토큰들 모두 검색 토큰으로 저장되고 검색어 "ho"라고만 검색을 하더라도 "house"가 포함된 도큐먼트들이 반환된다.
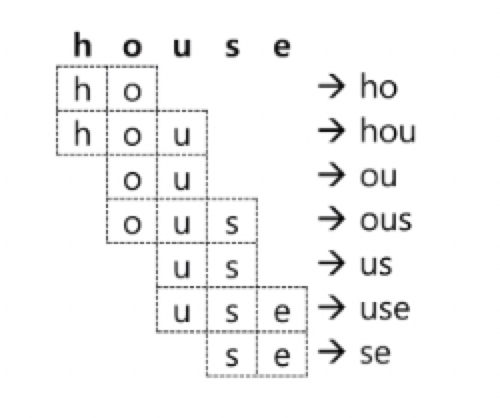
min_gram : 2, max_gram : 3 인 경우 왼쪽과 같다.
* ngram 토큰 필터를 사용하면 위처럼 저장되는 텀의 갯수가 기하급수적으로 늘어난다. 일반적인 텍스트 검색에는 사용하지 않는 것이 좋고 카테고리 목록이나 태그 목록과 같이 전체 개수가 많지 않은 데이터 집단에 자동완성 같은 기능을 구현할 때 적합하다.
실습
ngram_practice 라는 Index 설정
PUT ngram_practice
{
"settings": {
"analysis": {
"filter": {
"my_ngram_f": {
"type": "ngram",
"min_gram": 3,
"max_gram": 4
}
}
}
}
}"house" 분석
GET ngram_practice/_analyze
{
"tokenizer": "keyword",
"filter": [
"my_ngram_f"
],
"text": "house"
}결과
{
"tokens" : [
{
"token" : "hou",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 0
},
{
"token" : "hous",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 0
},
{
"token" : "ous",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 0
},
{
"token" : "ouse",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 0
},
{
"token" : "use",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 0
}
]
}
Edge NGram
단어의 앞쪽부터 저장하기 위해서 ("ho, "hou", "hous", "house" 요렇게) 는 Edge NGram 토큰 필터를 이용하면 된다.
설정하는 방법은 "type" : "edgeNGram"이다.

min_gram: 1 , max_gram: 4 로 설정해보는
실습해보기
edge_ngram_practice 라는 Index 설정
PUT edge_ngram_practice
{
"settings": {
"analysis": {
"filter": {
"my_ngram_f": {
"type": "edgeNGram",
"min_gram": 1,
"max_gram": 4
}
}
}
}
}"house" 분석
GET edge_ngram_practice/_analyze
{
"tokenizer": "keyword",
"filter": [
"my_ngram_f"
],
"text": "house"
}결과
{
"tokens" : [
{
"token" : "h",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 0
},
{
"token" : "ho",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 0
},
{
"token" : "hou",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 0
},
{
"token" : "hous",
"start_offset" : 0,
"end_offset" : 5,
"type" : "word",
"position" : 0
}
]
}
Shingle
문자 하나하나가 아니라 단어 단위로 구성된 묶음을 shingle 이라고 한다. 사용하는 설정은 "type": "shingle" 이다.
<shingle 토큰 필터의 옵션>
* min_shingle_size (default : 2) : 최소 단어 개수
max_shingle_size (default : 2) : 최대 단어 개수
output_unigrams (default: true) : shingle 외에도 각각의 개별 토큰도 저장하는지의 여부 설정
output_unigrams_if_no_shingles (default : false) : shingle을 만들 수 없는 경우에만 개별 토큰을 저장하는지의 여부 설정
token_separator (default : " ") : 토큰 구분자를 지정
filler_token (default : _ ) : shing을 만들 텀이 없는 경우 (보통 stop토큰 필터와 함께 사용되어 offset 위치만 있고 티 없는 경우) 대체할 텍스트를 지정

실습
PUT shingle_practice
{
"settings": {
"analysis": {
"filter": {
"my_shingle_f": {
"type": "shingle",
"min_shingle_size": 3,
"max_shingle_size": 4
}
}
}
}
}"동해물과 ~ 만쉐이" 분석
GET shingle_practice/_analyze
{
"tokenizer": "whitespace",
"filter": [
"my_shingle_f"
],
"text": "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만쉐이"
}결과
각각의 단어는 기본으로 분리를 하고 min size가 3이므로 세 개의 단어들 ~ 네 개의 단어들 모임으로 분석된다.
동해물과
동해물과 백두산이 마르고
동해물과 백두산이 마르고 닳도록
백두산이
백두산이 마르고 닳도록
백두산이 마르고 닳도록 하느님이
마르고
마르고 닳도록 하느님이
마르고 닳도록 하느님이 보우하사
닳도록
닳도록 하느님이 보우하사
닳도록 하느님이 보우하사 우리나라
하느님이
하느님이 보우하사 우리나라
하느님이 보우하사 우리나라 만쉐이
보우하사
보우하사 우리나라 만쉐이
우리나라
만쉐이
이제 ngram, edgengram, shingle을 검색 조건에 따라 적절히 사용하면 될 것 같다!
그게 어려울 것 같지만,,,,,,,,
References : https://esbook.kimjmin.net/06-text-analysis/6.6-token-filter/6.6.4-ngram-edge-ngram-shingle



