


Elastic ELK (Elasticsearch, Logstash, Kibana)
Elasticsearch
: 아파치 루씬 기반으로 JAVA로 개발된 분산형 RESTful 검색 및 분석 엔진
JAVA로 만들어져 JAVA 실행 가능한 환경이라면 어디서든 구동이 가능
오픈소스, 실시간 분석(real-time search), 전문 (full text) 검색 엔진, RESTful API, 멀티 테넌시, 역색인의 특징을 가짐
* 멀티 테넌시란?
- 서로 다른 인덱스들을 별도의 커넥션없이 하나의 질의로 묶어서 검색, 결과도 하나의 출력으로 도출할 수 있는 특징
Logstash
: 데이터 집계, 변환, 저장하는 오픈 소스 서버의 데이터 처리 파이프라인
데이터 수집을 위한 도구, Elasticsearch의 입력 수단으로 사용 시작
JRuby로 되어 있다. 루비 코드로 개발되어 JAVA 런타임 머신 위에서 돌아간다.
Elasticsearch 외에도 다양한 경로의 출력이 가능하기 때문에 Elasticsearch에 데이터를 색인하는 동시에 로컬 파일이나 아마존 aws S3 저장소로 동시에 송출도 가능하다.
Logstash는 데이터 처리를 아래와 같은 과정으로 한다.
입력 (Inputs) -> 필터 (Filters) -> 출력 (Outputs)
Kibana
: 데이터 시각화 도구
검색, aggregation의 집계 기능을 이용해 웹 도구로 시각화를 한다.
Elastic stack을 탐색하여 쿼리 부하 추적부터 앱을 통해 요청이 흐르는 방식 등을 볼 수 있음
Beats
: 경량 데이터 수집기, 구글이 개발한 Go 언어로 개발됨
너무 많은 기능을 가져 무거워진 Logstash에서 '전송'하는 기능을 따로 분리하기위해 탄생
Go언어는 매우 가볍고 바이너리 실행 파일로 컴파일 되는 언어라 라이브러리 종속성도 적다.
단일 목적의 데이터 수집기 플랫폼으로 수백 수천 개의 장비와 시스템으로부터 Logstash나 Elasticsearch에 데이터를 전송한다.
ex) Libbeat, Packetbeat, Filebeat, Metricbeat, Winlogbeat, Auditbeat, Heartbeat, Functionbeat, ,,
데이터 색인
헷갈리지만 아주 중요한 용어 알고가기
| 용어 | 설명 |
| 색인 (indexing) |
데이터가 검색될 수 있는 구조로 검색어 토큰들로 변환하여 저장하는 일련의 과정 |
| 인덱스 (index, indices) |
색인 과정을 거친 결과물(데이터)이 저장되는 저장소 mysql의 table, mongodb의 collection과 비슷한 개념 |
| 검색 (search) |
검색어 토큰들을 포함하고 있는 문서를 (인덱스 내에서) 찾는 과정 |
| 질의 (query) |
검색 시 입력하는 "검색어" or "검색 조건" |
Elasticsearch 시스템 구조
Elasticsearch는 대용량 데이터의 증가에 따른 스케일 아웃과 데이터 무결성 유지를 위한 클러스터링을 지원한다. 항상 클러스터를 기본으로 동작하고 1개의 노드만 있어도 클러스터로 구성이 된다.

클러스터 ⊃ 노드 ⊃ 인덱스 ⊃ 샤드
* Cluster, 클러스터란 ?
- Elasticsearch에서 가장 큰 시스템 단위를 의미
- 같은 cluster.name 속성을 가진 최소 하나 이상의 노드들의 집합
- 서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 시스템
- 여러 대의 서버가 하나의 클러스터 구성 or 하나의 서버에 여러 개의 클러스터 존재 가능
- 노드가 클러스터를 Join하거나 Leave할 때, 클러스터는 데이터를 사용가능한 노드들에게 균등하게 분배하기 위해 스스로를 재조직한다.
* Node, 노드란 ?
- Elasticsearch를 구성하는 하나의 단위 프로세스 의미
- 노드의 역할 : Master, Data, Ingest, Tribe
- 클러스터마다 하나의 마스터 후보 노드 (Master-eligible node)가 존재하며 만약 마스터 노드의 역할을 수행할 수 있는 노드가 없다면 클러스터는 작동이 정지된다.
| Nodes | |
| Master Node, 마스터 노드 node.master: true |
- 인덱스의 메타 데이터, 샤드의 위치와 같은 클러스터 상태 정보를 관리하는 역할 - 모든 노드는 마스터 노드로 선출될 수 있는 master eligible node, 마스터 후보 노드이다. - 마스터 노드가 어떤 이유로 네트워크상에서 다운되면, 마스터 후보 노드들은 이미 처음부터 마스터 노드의 정보들을 공유하고 있기 때문에 선출 즉시 마스터 역할을 수행가능하다. - 클러스터가 점점 커져서 너~무 많은 노드와 샤드들이 생겨 모두 정보를 공유하다보면 비효율적이므로 마스터 노드의 역할을 수행할 예비 후보 노드들만 따로 node.master: true로 (디폴트값) 설정하고 나머지 노드들은 node.master: false로 설정해 주는 것이 좋다. |
| Data Node, 데이터 노드 node.data:true |
- 실제로 색인된 데이터를 저장하고 있는 노드 - 마스터 후보 노드들은 node.data: false 로 설정하여 데이터를 저장하지 않고 "마스터 노드" 역할만 하도록 해서 각자의 업무를 명확하게 나눌 수 있다. |
| node.ingest: true | - 데이터 색인 시 전처리 작업인 ingest pipeline 작업의 수행을 할 수 있는지 여부를 지정 - false인 경우 해당 노드에서는 ingest pipeline 작업의 실행이 불가능함 |
| node.ml:true | - 머신러닝 작업 수행을 할 수 있는지 여부 설정 - false인 경우 해당 노드에서는 머신러닝 작업이 수행되지 않음 |
예시) 전용 마스터 노드 설정 |
config/elasticsearch.yml node.master: true node.data: false node.ingest: false node.ml: false 위와 같은 방법으로 클러스터 안의 노드들을 마스터 전용, 데이터 전용 등으로 분리하여 유연한 구성 가능 |
* index, 인덱스란 ?
- 단일 데이터 단위 도큐먼트(document)를 모아놓은 집합
- 인덱스는 기본적으로 shard, 샤드라는 단위로 분리되고 각 노드에 분산되어 저장된다.
- 각 인덱스는 하나 이상의 샤드로 이루어진다. (7.0v 부터는 인덱스를 생성할 때 별도의 설정을 하지 않으면 디폴트로 1개의 샤드가 할당됨, 6.x 이하 버전에서는 5개)
* Shard, 샤드란 ?
- 루씬의 단일 검색 인스턴스
- 처음 생성된 샤드를 Primary Shard, 복제본은 Replica라고 부른다.
- 데이터를 분산해서 저장하는 방법을 의미 (index를 여러 shards로 쪼갠 것)
- 샤드란 Elasticsearch가 클러스터에서 데이터를 배포하는 단위
- 인덱스를 처음 생성할 때 지정할 수 있고 인덱스를 재색인 하지 않는 이상 수정 불가하다. (shards는 불가, replicas 복제본의 수는 나중에 변경 가능)
- Elasticsearch 클러스터에 있는 데이터의 하위 집합에 대한 쿼리를 색인하고 처리하는 자체 포함 검색 엔진
- replica는 또 다른 형태의 shard라고 할 수 있음 -> shard의 복제본 = replica -> replica는 서로 다른 노드에 존재할 것을 권장
- * 노드가 1개만 있는 경우 프라이머리 샤드만 존재하고 복제본은 생성되지 않음 -> Elasticsearch는 아무리 작은 클러스터라도 데이터 가용성과 무결성을 위해 최소 3개의 노드로 구성할 것 을 권장
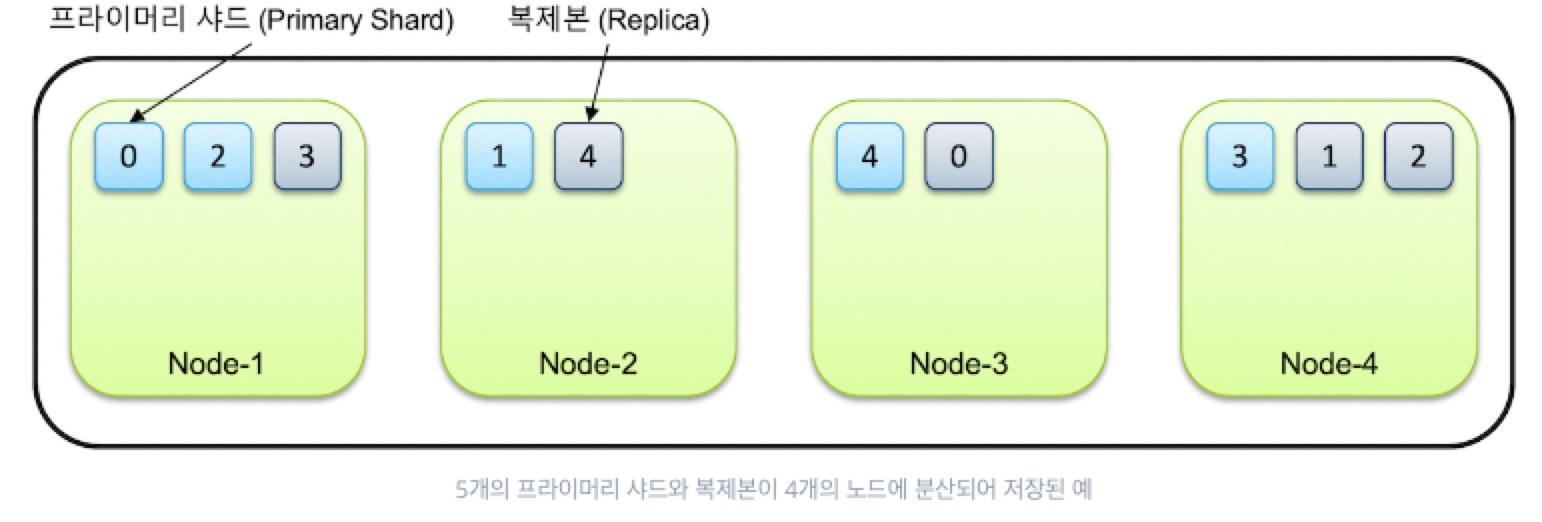
- 같은 샤드와 복제본은 동일한 데이터를 담고 있으며 반드시 서로 다른 노드에 저장이 된다. -> 덕분에 하나의 노드가 시스템 다운이나 네트워크 단절 등으로 사라지게 되더라도 다른 노드 안에 해당 데이터들이 있게 되어 유실 확율이 적어진다.
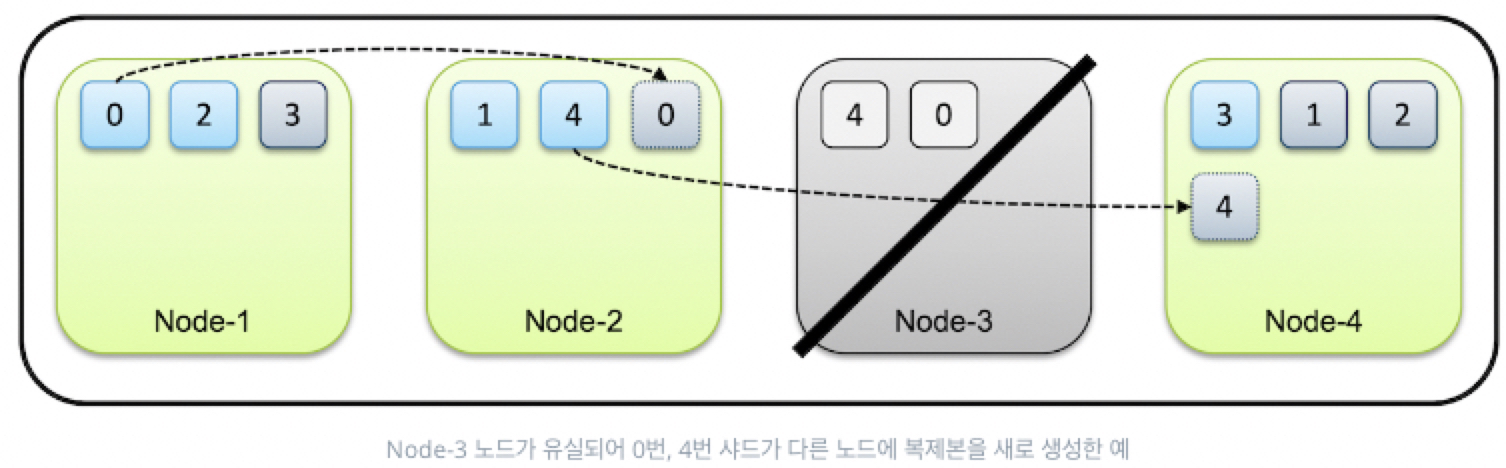
위의 그림과 같이 Node-3이 사라지면 안에 있던 shard 0과 shard 4는 각각 Node-1, Node2에 존재하므로 데이터 유실이 일어나지 않는다. 클러스터는 유실된 노드가 복구되기를 기다렸다가 타임아웃이 지나버리고 복구되지 않는다고 판단하면 바로 한 개씩만 남아버린 shard 0과 shard 4의 replica shard를 다른 노드에 생성한다. 이 때 생기는 shard들은 모두 replica로 primay는 기존에 남아있던 shard가 담당하게 된다.
클러스터, 노드, 샤드의 관계
- 단일 노드의 경우

만약 위의 그림처럼 a single instance of Elasticsearch를 운영하면 단 하나의 노드가 있는 한 개의 클러스터를 갖게 되는데 모든 primary shards가 하나의 노드에 있기 때문에 replica shards가 할당될 수 없다.
-> 클러스터 상태가 노랑색을 띠게됨 : 클러스터 기능 자체에 문제는 없지만 데이터 손실에 대한 위험이 있다.
- 여러 노드의 경우
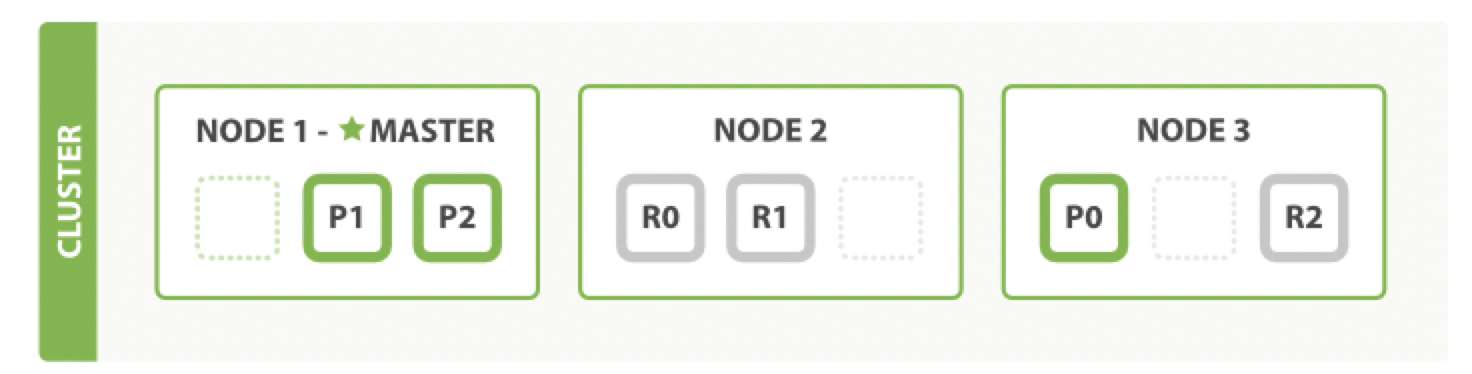
하나의 클러스터에 여러 노드를 추가하면 클러스터의 수용능력과 신뢰성도 높아진다. 디폴트로 노드는 data node이자 클러스터를 컨트롤하는 마스터 노드로 선출될 예비 노드이기도 하다. 노드의 특정한 목적을 위해 사용자가 직접 구성할 수도 있다. 위의 그림처럼 하나 이상의 더 많은 노드들을 클러스터에 추가할 때, 자동으로 replica shards가 할당되고 모든 privary 와 replica shards가 활성상태일 때 클러스터의 상태는 초록색이 된다.
References : Elasticsearch을 이해하는데 있어 큰 도움을 받은 Es가이드북
Elastic 가이드 북 - Elastic 가이드북
7. 인덱스 설정과 매핑 - Settings & Mappings
esbook.kimjmin.net
https://www.elastic.co/guide/en/elasticsearch/reference/current/add-elasticsearch-nodes.html
Add and remove nodes in your cluster | Elasticsearch Guide [8.4] | Elastic
Voting exclusions are only required when removing at least half of the master-eligible nodes from a cluster in a short time period. They are not required when removing master-ineligible nodes, nor are they required when removing fewer than half of the mast
www.elastic.co
'Elasticsearch' 카테고리의 다른 글
| [elasticsearch] match_all, match, match_phrase 사용 방법 및 차이점 (0) | 2022.11.07 |
|---|---|
| [elasticsearch] preference 사용해야 하는 이유 / 방법 및 예제 알아보기 (0) | 2022.11.01 |
| [elasticsearch] 필드 값이 존재하지않는 경우 query 만들기 (0) | 2022.10.28 |
| [Elasticsearch] Data Math 개념과 계산하는 방법 (0) | 2022.10.24 |
| [Elasticsearch] analyzer [ ] contains filters [ ] that are not allowed to run in index time mode (0) | 2022.09.05 |



